SEO e IA
12 de fev. de 2026
Go back
Como criar uma camada semântica AI-first no Framer usando Cloudflare Workers
Autor: Rafael Lins
Como contornar as limitações do Framer Basic usando Cloudflare Workers no plano gratuito e transformar seu site em uma arquitetura preparada para AI Search, IndexNow e visibilidade para LLMs.

O crescimento dos mecanismos de busca baseados em IA está mudando completamente a forma como sites precisam se estruturar tecnicamente.
Hoje, não basta mais apenas trabalhar:
title
meta description
schema markup
sitemap.xml
backlinks
Plataformas como:
ChatGPT
Gemini
Claude
Perplexity
Google AI Overviews
começaram a consumir conteúdo de maneira muito mais contextual, semântica e orientada a entidades.
Isso criou uma nova necessidade técnica:
construir uma camada semântica preparada para IA.
E foi exatamente isso que comecei a implementar na infraestrutura da Ad Rock utilizando:
Framer
Cloudflare Workers
endpoints machine-readable
semantic edge infrastructure
AI Discovery
Neste artigo vou mostrar como essa arquitetura funciona, quais problemas ela resolve e como ela pode ser utilizada em projetos modernos de SEO técnico orientado para IA.
O problema inicial do Framer para AI-first SEO
O Framer evoluiu muito nos últimos anos em:
performance
renderização
SEO tradicional
sitemap.xml
robots.txt
estrutura semântica
Mas ainda existem limitações importantes quando falamos de AI Discovery.
Principalmente porque o Framer não permite facilmente:
criação de endpoints customizados
APIs semânticas
arquivos JSON machine-readable avançados
controle granular de headers
infraestrutura para crawlers de IA
edge semantic orchestration
Na prática, isso dificulta criar arquivos como:
llms.txt
ai-dataset.json
schema endpoints
visibility logs
knowledge maps
Foi aí que os Cloudflare Workers entraram.
A arquitetura final do projeto
A arquitetura final ficou dividida em duas camadas.
Frontend principal
Responsável por:
páginas
CMS
blog
sitemap.xml
renderização
SEO tradicional
Tudo continua sendo servido normalmente pelo Framer.
Camada semântica AI-first
Responsável por:
llms.txt
ai-dataset.json
schema-endpoint.json
security.txt
humans.txt
AI visibility
bot orchestration
semantic endpoints
Essa separação acabou sendo muito mais elegante e robusta do que tentar interceptar todo o domínio principal.
Por que não interceptar o domínio principal?
Inicialmente a ideia era usar:
como rota global no Worker.
Na prática isso gerou alguns problemas.
O Framer utiliza uma arquitetura moderna de edge hosting e CDN, e em alguns cenários:
o Framer tomava precedência sobre o Worker
havia conflito de roteamento
alguns endpoints retornavam 404
existia risco de loop de proxy reverso
Especialmente porque o Worker fazia fetch do próprio domínio:
Isso poderia gerar:
O resultado final foi muito mais limpo quando a arquitetura passou a usar um subdomínio dedicado:
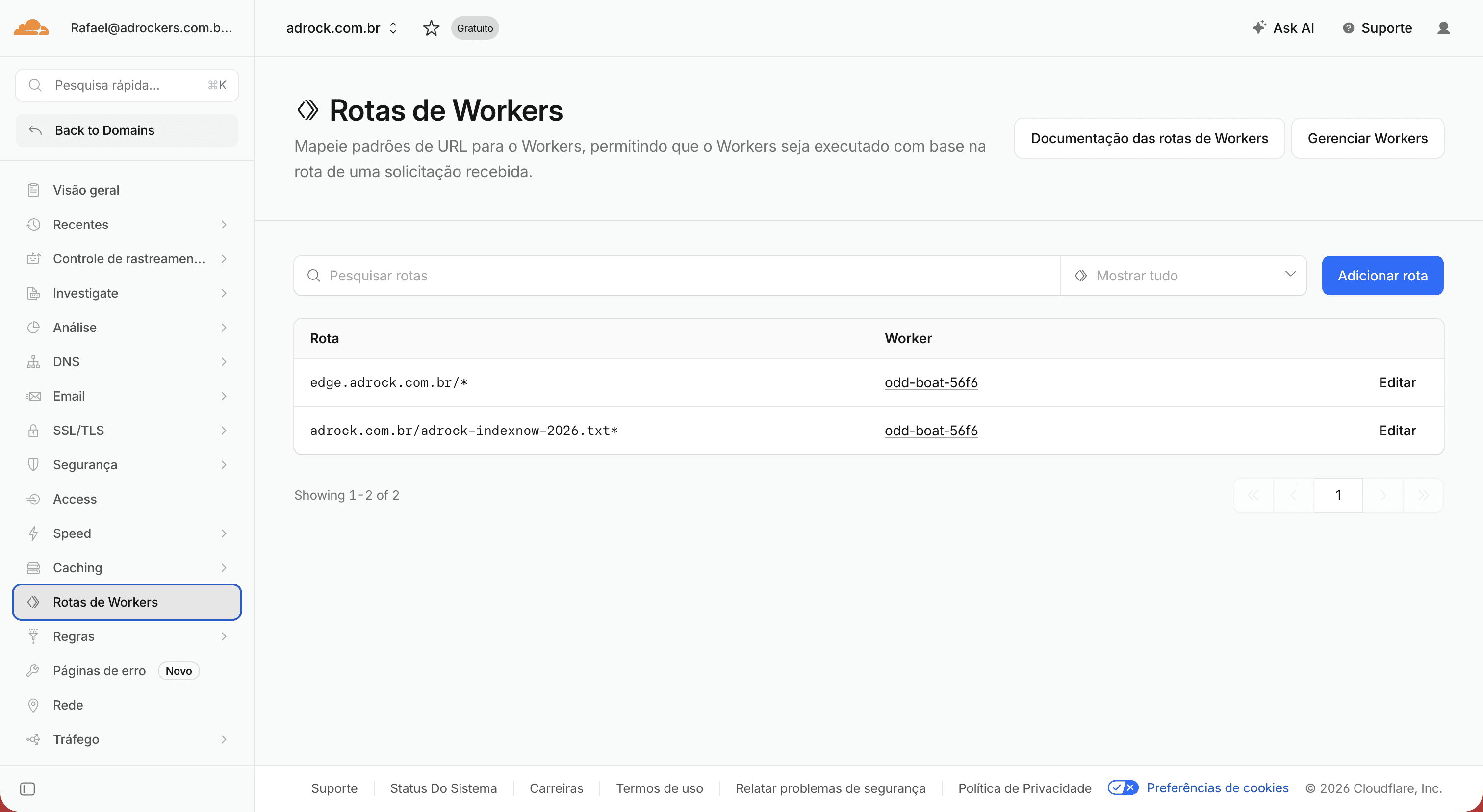
O conceito de Semantic Edge Infrastructure
O projeto acabou evoluindo para algo maior do que apenas “corrigir limitações do Framer”.
Na prática foi criada uma:
Uma camada desacoplada do frontend responsável exclusivamente por:
AI Discovery
semantic crawling
machine-readable SEO
AI endpoints
organização contextual
exposição de entidades
Essa abordagem conversa muito melhor com a nova geração de mecanismos baseados em IA.
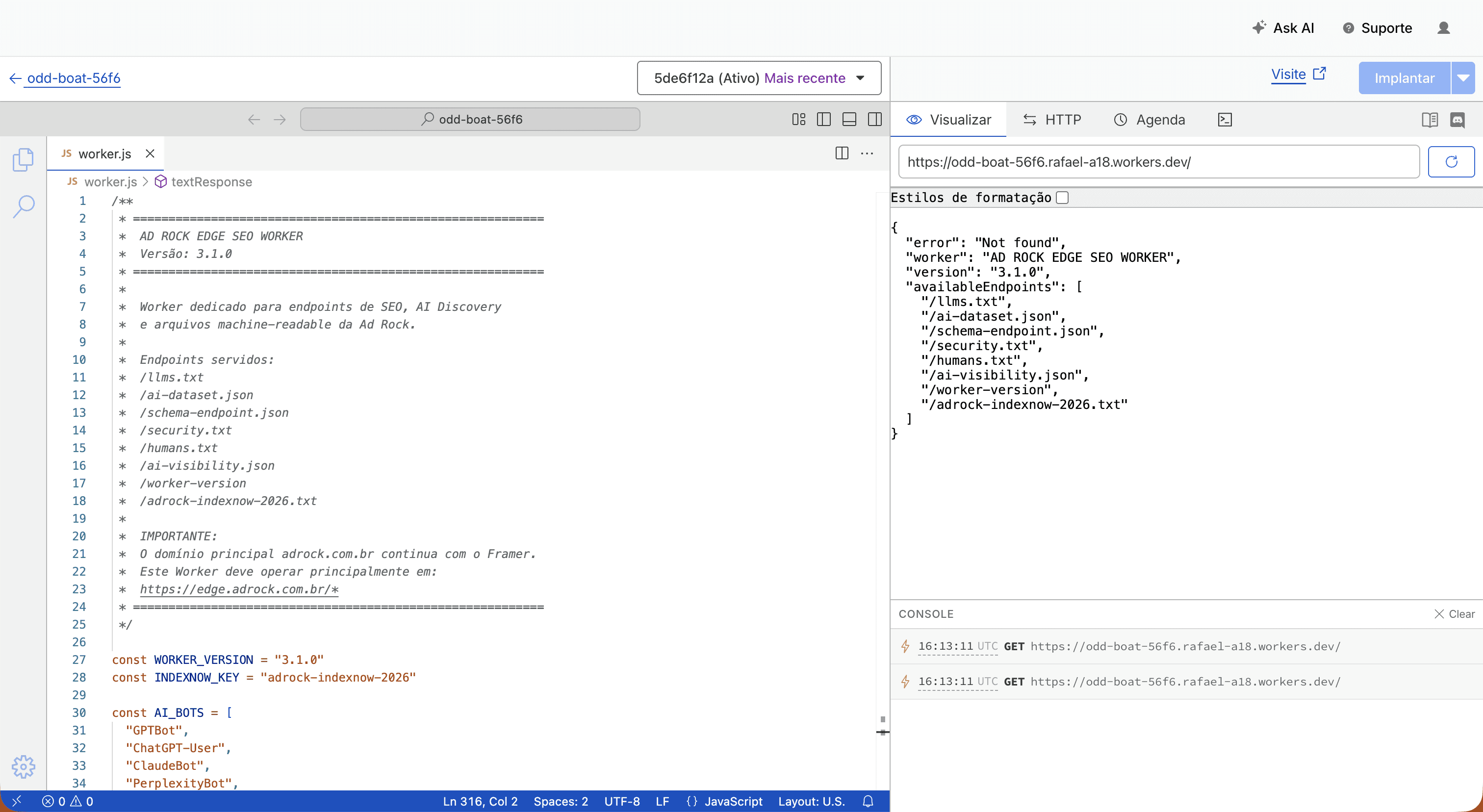
O llms.txt da Ad Rock
Um dos principais endpoints implementados foi:
O objetivo do arquivo é fornecer contexto semântico estruturado para sistemas de IA.
Exemplo simplificado:
Além disso o arquivo também inclui:
áreas de especialização
contexto institucional
semantic linking
endpoints recomendados
discovery de feeds
Isso ajuda:
ChatGPT
Gemini
Claude
Perplexity
AI crawlers
a entenderem melhor:
a marca
os serviços
as entidades
o contexto do site
O ai-dataset.json
Outro endpoint importante foi:
Ele funciona como um dataset machine-readable da organização.
Exemplo:
Esse endpoint permite:
AI ingestion
semantic retrieval
entity mapping
contextual indexing
O schema-endpoint.json
O projeto também passou a expor um endpoint dedicado de schema:
Isso facilita:
consumo programático
integração futura
machine-readable organization data
semantic graph linking
Headers específicos para IA
Outra vantagem dos Workers foi o controle total de headers.
Exemplo:
Isso melhora:
observabilidade
debug
AI crawler compatibility
cache control
Logging de bots de IA
O Worker também implementa:
logging de bots
rate limiting
AI visibility
métricas básicas
Exemplo de endpoint:
Isso abre espaço para futuras análises sobre:
frequência de crawling
User-Agents de IA
padrões de acesso
AI indexing
Versionamento do Worker
Outro ponto importante foi criar:
Isso facilita:
auditoria
rollback
controle de versões
troubleshooting
Por que essa arquitetura faz sentido para AI Search?
Porque os mecanismos modernos estão trabalhando muito além do SEO clássico.
Hoje existe forte crescimento em:
entity-first SEO
semantic retrieval
AI Discovery
contextual indexing
RAG ingestion
semantic crawling
A arquitetura baseada em Workers permite criar exatamente essa camada intermediária entre:
o frontend
e os sistemas de IA
O que essa arquitetura evita
A separação entre Framer e Edge também evita:
conflitos de CDN
loops de proxy
quebra de assets
problemas de cache
interceptação global do site
degradação de performance
Próximos passos da infraestrutura
A estrutura atual já funciona bem, mas existem evoluções planejadas.
knowledge-graph.json
Mapeamento de:
entidades
serviços
tecnologias
parceiros
autores
entities.json
Catálogo semântico das entidades do ecossistema Ad Rock.
services.json
Serviços expostos de forma machine-readable.
content-map.json
Mapa semântico do blog e conteúdos.
ai-rss.xml
Feed específico para AI Discovery.
Conclusão
O projeto começou como uma tentativa de complementar algumas limitações do Framer.
Mas acabou evoluindo para uma infraestrutura semântica muito mais avançada.
Hoje a arquitetura da Ad Rock possui:
semantic edge infrastructure
AI-first SEO layer
llms.txt
ai-dataset.json
machine-readable endpoints
AI Discovery architecture
observabilidade para crawlers de IA
Tudo isso utilizando:
Framer
Cloudflare Workers
edge computing
semantic endpoints
O mais interessante é que essa abordagem cria uma camada preparada não apenas para buscadores tradicionais.
Mas principalmente para a próxima geração de mecanismos baseados em IA.






Go back